Planning-Agents
This repo demonstrates planning capability of agents along with browser automation using MCP and human in the loop features
GitHubスター
0
ユーザー評価
未評価
お気に入り
0
閲覧数
48
フォーク
0
イシュー
0
Project Name: Agentic Browser Automation Framework
1. Overview
This project implements a sophisticated autonomous agent designed to understand user goals and execute them by automating interactions with a web browser. It combines the power of Large Language Models (LLMs) for planning and reasoning with a robust execution framework, enabling it to tackle complex, multi-step tasks such as web scraping, form submission, and site navigation.
The agent's intelligence is rooted in two core principles:
- Planning and Decomposition: Instead of reacting to stimuli one at a time, the agent first creates a detailed, step-by-step plan to achieve the user's objective. It decomposes a goal like "Subscribe to the newsletter on inker.ai with my email" into a sequence of concrete actions:
navigate to URL,find contact button,click button,find email field,input text, etc. This plan is dynamically updated as the agent receives new information. - Effective Prompting: The agent's behavior is guided by a set of meticulously crafted prompts that instruct the LLM on how to reason at each stage of the task. These prompts provide the model with context, available tools, rules, and examples, ensuring its output is structured, relevant, and safe to execute.
CONTENTS -
- 1. Overview
- 2. Tasks Execution
- 3. Effective Prompting for Planning Agent
- 4. Code Flow and Architecture
- 5. Specialty Feature: Human in the Loop
- 6. Prompts Analysis (
prompts/)
2. Tasks Execution
In below demo I have covered 4 tasks -
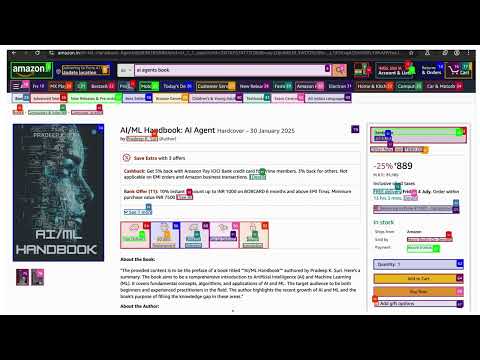
- 2.1 MCD order placement - Using MCP and Agents to add items to cart on MCD website
- 2.2 Amazon order - Search for a product on Amazon and add to cart
- 2.3 Split PDF to Images - Using MCP and Agents to split a PDF to images. This requires human intervention to select the file as scope of project is limited to browser automation only.
- 2.4 GitHub Repository Creation - Using MCP and Agents to create a new repository on GitHub. This requires human intervention to sign in as scope of project is limited to browser automation only. Sign in can be done by agent as well but for demo purpose I have kept it as human intervention.
NOTE - The prompts used in this demo can be found in HOWTORUN.md file.
3. Effective Prompting for Planning Agent
A new prompt - prompts/planning_agent_prompt.txt - has been created to develop more detailed tasks and subtasks needed to complete user goal -
USER QUERY -
I am a middle school physics teacher preparing to teach the law of conservation of momentum. Could you create a series of clear and accurate demonstration animations and organize them into a simple presentation html?
OUTPUT WITH NEW PROMPT -
# 📌 Conservation of Momentum Demo Animations and Presentation
## 1. Goal Understanding and Scope Framing
- [ ] Define the primary goal: To create a series of demonstration animations illustrating the law of conservation of momentum for middle school physics students.
- [ ] Define the intended audience: Middle school physics students with little to no prior knowledge of momentum.
- [ ] List constraints: Animations must be visually clear, accurate, and easily understandable. The final deliverable is an HTML presentation that can be displayed in a classroom setting. Focus on 2D animations for simplicity.
## 2. Core Task Breakdown
- [ ] Design a simple animation showing a single object moving at a constant velocity.
- [ ] Animate the object moving in a straight line, with a clear indication of its velocity (e.g., a velocity vector).
- [ ] Add a clear display of the object's mass and velocity.
- [ ] Calculate and display the object's momentum.
- [ ] Design an animation of an elastic collision between two objects of different masses.
- [ ] Animate two objects approaching each other.
- [ ] Show the objects colliding and bouncing off each other.
- [ ] Display the mass and velocity of each object before and after the collision.
- [ ] Calculate and display the total momentum of the system before and after the collision to demonstrate conservation.
- [ ] Include a text overlay that explicitly states that the total momentum is conserved.
- [ ] Design an animation of an inelastic collision between two objects of different masses where the objects stick together.
- [ ] Animate two objects approaching each other.
- [ ] Show the objects colliding and sticking together to form a single object.
- [ ] Display the mass and velocity of each object before the collision.
- [ ] Calculate and display the velocity of the combined object after the collision.
- [ ] Calculate and display the total momentum of the system before and after the collision to demonstrate conservation.
- [ ] Include a text overlay that explicitly states that the total momentum is conserved.
- [ ] Design an animation of an explosion where a single object breaks into two objects.
- [ ] Animate a single object at rest.
- [ ] Show the object exploding into two objects moving in opposite directions.
- [ ] Display the mass and velocity of each object after the explosion.
- [ ] Calculate and display the total momentum of the system after the explosion to demonstrate conservation.
- [ ] Include a text overlay that explicitly states that the total momentum is conserved.
## 3. Output Structuring and Format Planning
- [ ] Structure the HTML presentation with a clear title and introduction.
- [ ] Dedicate a separate section/slide for each animation.
- [ ] Embed each animation as an HTML5 `<canvas>` element or an animated GIF/video.
- [ ] Include descriptive text explaining the physics concepts demonstrated in each animation.
- [ ] Add simple controls (play/pause) for each animation if using `<canvas>`.
- [ ] Use clear and concise language appropriate for middle school students.
- [ ] Choose a visually appealing and uncluttered design for the presentation.
- [ ] Ensure the presentation is responsive and works on different screen sizes.
## 4. Finalization and Quality Check
- [ ] Verify the accuracy of all physics calculations and animations.
- [ ] Ensure that the animations are visually clear and easy to understand.
- [ ] Test the presentation on different browsers and devices.
- [ ] Check for any typos or grammatical errors in the text.
- [ ] Self-evaluate for completeness, redundancy, and clarity.
- [ ] Final Deliverable: A single, well-structured HTML file containing the animations and explanatory text.
4. Code Flow and Architecture
The application's entry point is main.py, but the core logic resides within the AgentLoop class (agent/agent_loop3.py). This loop orchestrates the interaction between several key components in a Perception-Decision-Action cycle.
Key Components:
AgentLoop: The central coordinator. It initializes all other components and manages the end-to-end execution flow for a given query. It maintains the agent's state through aContextManagerinstance.MultiMCP(mcp_servers/multiMCP.py): A dispatcher that manages connections to various "MCP" (Multi-Capability Provider) servers. These servers expose tools to the agent, such as the browser control tools. The agent doesn't call browser functions directly; it sends requests to theMultiMCP, which routes them to the appropriate tool server.ContextManager(agent/contextManager.py): A critical data structure that maintains the state of the task. It holds the original query, a graph of the plan (nodes are steps), the results of executed steps, and aglobalsdictionary for sharing information (like browser state or extracted data) across steps.
The Execution Cycle:
Initialization (
main.py->AgentLoop.__init__):- The user starts the
interactive()session inmain.py. - The
MultiMCPis initialized with server configurations fromconfig/mcp_server_config.yaml. - An
AgentLoopinstance is created, which in turn initializes thePerception,Decision, andSummarizercomponents, each with its corresponding prompt file.
- The user starts the
Initial Perception (
AgentLoop.run):- When the user provides a query, the loop begins.
- Input: The user's query and any relevant long-term
memory. - The
Perceptioncomponent is called. Guided byprompts/perception_prompt.txtin"user_query"mode, it analyzes the query to determine the overall goal and the best way to approach it. - Output: The key output is a
route, which is eitherdecision(for general tasks),browserAgent(for browser tasks), orsummarize(if the query can be answered immediately).
The Decision-Action Loop (
AgentLoop._run_decision_loop):- Decision:
- Input: The context (plan graph, previous results) and the route from
Perception. - The
Decisioncomponent is called. Using eitherdecision_prompt.txtor the more specializedbrowser_decision_prompt.txt, the LLM generates a plan. - Output: A plan graph with nodes representing steps, and a dictionary of
code_variantsfor the next step to be executed (next_step_id). Providing multiple variants (A,B,C) gives the agent a fallback mechanism if one approach fails.
- Input: The context (plan graph, previous results) and the route from
- Action (
execute_step_with_mode):- Input: The
next_step_idandcode_variantsfrom theDecisioncomponent. - The function attempts to execute the code for the step. In the default
fallbackmode, it tries variantA, thenB, thenCuntil one succeeds. The code itself is run in a sandboxed environment viaaction/executor.py. - Output: The result of the code execution (data, browser state, or an error). This result is attached to the corresponding step in the
ContextManager.
- Input: The
- Post-Action Perception:
- Input: The updated context, including the result of the action.
- The
Perceptioncomponent is called again, this time in"step_result"mode. It analyzes the outcome of the action. - Output: It determines if the overall goal is now complete (
route="summarize"), or if more steps are needed (route="decision"orroute="browserAgent").
- The loop repeats, feeding the output of
Perceptionback into theDecisioncomponent to generate the next step, until the goal is achieved or a failure condition is met (e.g., max iterations).
- Decision:
Summarization (
AgentLoop._summarize):- Once the
Perceptioncomponent determines the goal is achieved, the loop terminates. - Input: The full context from the
ContextManager. - The
Summarizercomponent is called to generate a cohesive, human-readable summary of the task and its outcome. - Output: The final answer that is presented to the user.
- Once the
5. Specialty Feature: Human in the Loop
When the agent encounters a situation it cannot handle programmatically—such as a CAPTCHA, a complex file upload, or a two-factor authentication prompt—it can seamlessly hand control over to a human.
How it Works:
- Availability: The
human_in_the_loop(reason: str)function is defined inaction/executor.py. It is not called directly by the agent's internal logic. Instead, it is securely injected into the sandboxed global environment where the LLM-generated code is executed (build_safe_globalsfunction).
async def human_in_the_loop(reason: str):
"""
Pauses execution and waits for human intervention.
"""
try:
log_step(f"🚨 HUMAN INTERVENTION NEEDED: {reason}", symbol="👤")
log_step("Please perform the required action in the browser, then type 'Done' and press Enter.", symbol="⌨️")
def get_input():
return input("➡️ Type 'Done' to continue: ")
future = asyncio.to_thread(get_input)
response = await asyncio.wait_for(future, timeout=120.0)
if response.strip().lower() == "done":
log_step("✅ Human intervention complete. Resuming...", symbol="👍")
return "Human intervention successful."
else:
raise Exception("Human did not confirm with 'Done'. Aborting.")
except asyncio.TimeoutError:
log_error("⌛ Timeout: Human did not respond within 30 seconds. Aborting.")
raise Exception("Human intervention timed out.")
except Exception as e:
log_error(f"An error occurred during human intervention: {e}")
raise
- Decision to Use: The
prompts/browser_decision_prompt.txtexplicitly instructs the LLM on when and how to use this function. The model learns to generate code that callshuman_in_the_loop('Please solve the CAPTCHA and click submit')as a step in its plan.
### **🤖 HUMAN INTERVENTION**
When a task cannot be completed with browser tools alone (e.g., file uploads, complex logins), use the `human_in_the_loop` function.
- `human_in_the_loop(reason: str)`: Pauses the agent and asks the user to perform a manual step.
- **MUST be the LAST action** in a code block.
- **MUST capture the result.**
- The `reason` should be a clear instruction for the human.
- The agent will wait for 30 seconds for the user to type "Done". If not, the process will fail.
Example:
`result = human_in_the_loop('Please upload the file resume.pdf and click "Submit"')`
`return {'human_action_0A': result}`
- Execution: When this generated code is executed, the
human_in_the_loopfunction is invoked.- It prints the
reasonto the console, instructing the user on what to do. - The agent's execution is paused, awaiting user input.
- The user performs the manual action in the browser.
- The user types
"Done"in the console and presses Enter.
- It prints the
{
"run_id": "8df1a9fb-1978-45e7-a4d9-e13c38748a22-P",
"snapshot_type": "step_result",
"entities": [
"GitHub",
"Sign in",
"New repository",
"Planning-Agents",
"browser automation"
],
"result_requirement": "Successfully create a new GitHub repository named 'Planning-Agents' with the specified description.",
"original_goal_achieved": false,
"reasoning": "The agent has successfully navigated to GitHub, clicked on 'Sign in', and the human has signed in. The next steps are clicking the 'New' button, filling the repository name and description, and clicking 'Create repository'. This is a multi-step browser workflow and requires browserAgent.",
"local_goal_achieved": true,
"local_reasoning": "The next steps require browser actions such as waiting for human input, clicking, filling forms, and navigating between pages, which fall under browser automation. Persisting with browserAgent since its progress.",
"last_tooluse_summary": "Human intervention via browserAgent was successful.",
"solution_summary": "Not ready yet",
"confidence": "0.90",
"route": "browserAgent",
"timestamp": "...",
"return_to": ""
}
- Resumption: The function returns a success message, and the
AgentLoopcontinues to the next step in its plan, now with the benefit of the human's intervention.
6. Prompts Analysis (prompts/)
The prompts are the "brain" of the agent, guiding the LLM's reasoning.
perception_prompt.txt: Governs the agent's self-awareness. In"user_query"mode, it helps the agent understand the user's intent. In"step_result"mode, it helps the agent understand the outcome of its own actions, checking for success, failure, or unexpected changes in the environment. It enforces persistence, ensuring that once the agent starts abrowserAgenttask, it doesn't get distracted.decision_prompt.txt: The general-purpose planning prompt. It instructs the LLM on how to create a graph of steps and generate Python code for each step.browser_decision_prompt.txt: A highly specialized and detailed prompt for browser automation. It is the most complex prompt and contains:- Tool Documentation: A list of all available browser functions (
open_url,click_element_by_index,input_text_by_index, etc.). - State Invalidation Rule: A critical rule that reminds the agent that after any navigation action, all previously identified element IDs are obsolete and the browser state must be captured again.
- Human in the Loop Instructions: Clear documentation for the
human_in_the_loopfunction, explaining when to use it (e.g., for file uploads, complex logins) and how to format the call. - Return Format Rules: Strict rules on how the generated code must format its
returnstatement to pass state information (e.g.,return {"page_state_0A": result}) correctly.
- Tool Documentation: A list of all available browser functions (
summarizer_prompt.txt: Guides the LLM in synthesizing the entire task history from theContextManager—including the initial query, all actions taken, and all results observed—into a final, concise answer for the user.